В этом руководстве показано, как использовать регулярные выражения для удаления части содержимого текстовой ячейки в Excel.
Вы когда-нибудь задумывались, насколько мощным был бы Excel, если бы кто-нибудь мог обогатить его набор инструментов регулярными выражениями? Мы не только подумали, но и поработали над этим :) А теперь вы можете добавить эту замечательную функцию RegEx в свои собственные книги и использовать регулярные выражения, чтобы удалить часть текста, соответствующего шаблону!
Ранее мы рассмотрели, как использовать регулярные выражения для замены текста в Excel. Для этого мы создали специальную функцию Regex Replace. Как оказалось, функция выходит за рамки своего основного предназначения и может не только заменять строки, но и удалять их. Как такое могло быть? С точки зрения Excel, удаление значения – это не что иное, как замена его пустой строкой, в чем функция Regex очень хороша!
- Функция VBA RegExp для удаления символов и текста в Excel
- Удалить все совпадения или конкретное совпадение
- Регулярное выражение для удаления определенных символов
- Удаляем группы символов с помощью регулярного выражения
- Регулярное выражение для удаления нечисловых символов
- Регулярное выражение для удаления всего после пробела
- Удаление текста после определенного символа
- Регулярное выражение для удаления всего до пробела
- Регулярное выражение для удаления всего перед символом
- Регулярное выражение для удаления всего, кроме
- Удаление HTML тегов в Excel при помощи регулярных выражений
- Инструмент удаления символов и текста Ablebits Regex
- Как удалить текст в скобках с помощью регулярного выражения
Функция VBA RegExp для удаления символов и текста в Excel
Как мы все знаем, регулярные выражения не поддерживаются в Excel по умолчанию. Чтобы включить их, вам необходимо создать свою собственную пользовательскую функцию. Хорошая новость в том, что такая функция уже написана, протестирована и готова к использованию. Все, что вам нужно сделать, это скопировать этот код , вставить код в редактор VBA, а затем сохранить файл как книгу с поддержкой макросов (.xlsm).
Функция имеет следующий синтаксис:
RegExpReplace (текст; шаблон; замена; [instance_num]; [match_case])
Первые три аргумента являются обязательными, два последних - необязательными.
Где:
- Текст – текстовая строка для поиска.
- Шаблон – регулярное выражение для поиска.
- Замена – текст, на который нужно заменить. Чтобы удалить подстроки, соответствующие шаблону, используйте для замены пустую строку ("").
- Instance_num (необязательно) – экземпляр, который нужно заменить. Если не указан, заменяются все найденные совпадения (по умолчанию).
- Match_case (необязательно) – логическое значение, указывающее, следует ли учитывать регистр текста или игнорировать его. Для сопоставления с учетом регистра используйте ИСТИНА (по умолчанию); для нечувствительности к регистру – ЛОЖЬ.
Для получения дополнительной информации см. Функцию RegExpReplace .
Как упоминалось выше, чтобы удалить части текста, соответствующие шаблону, вы должны заменить их пустой строкой. Итак, общая формула принимает такую форму для удаления текста:
RegExpReplace(текст, шаблон; ""; [instance_num]; [match_case])
В приведенных ниже примерах показаны различные способы применения этой базовой концепции.
Удалить все совпадения или конкретное совпадение
Функция RegExpReplace предназначена для поиска всех подстрок, соответствующих заданному регулярному выражению. То, какие вхождения следует удалять, определяется четвертым необязательным аргументом с именем instance_num.
По умолчанию это «все совпадения». Если аргумент instance_num опущен, все найденные совпадения удаляются. Чтобы удалить конкретное, укажите его порядковый номер.
Предположим, вы хотите удалить нумерацию в приведенных ниже строках. Все такие числа начинаются со знака решетки (#) и содержат ровно 5 цифр. Итак, мы можем идентифицировать их с помощью этого регулярного выражения:
Шаблон: #\d{5}\b
Граница слова \b указывает, что соответствующая подстрока не может быть частью более длинной строки, например #10000001.
Чтобы удалить все совпадения, аргумент instance_num не определен:
=RegExpReplace(A5; $A$2; "")
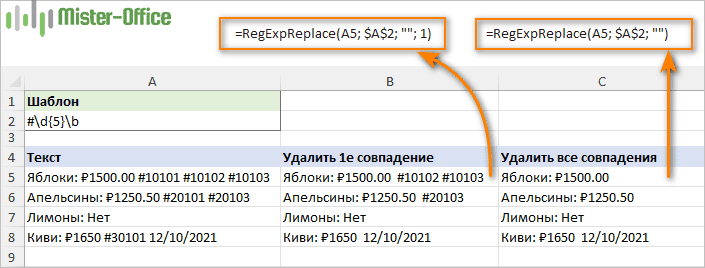
Чтобы исключить только первое вхождение, мы устанавливаем аргумент instance_num равным 1:
=RegExpReplace(A5; $A$2; ""; 1)
Обе эти формулы вы видите на скриншоте выше.
Регулярное выражение для удаления определенных символов
Чтобы удалить определенные символы из строки, просто запишите все эти ненужные символы и разделите их вертикальной чертой | . Она действует в регулярных выражениях как оператор ИЛИ.
Например, чтобы стандартизировать телефонные номера, записанные в различных форматах, сначала мы избавляемся от определенных символов, таких как круглые скобки, дефисы, точки и пробелы.
Шаблон: \(|\)|-|\.|\s
Формула будет для нашего примера такая:
=RegExpReplace(A5; “\(|\)|-|\.|\s”; “”)
Результатом этой операции является 10-значное число, например «1234567890».
Для удобства вы можете ввести регулярное выражение в отдельную ячейку и ссылаться на неё, используя абсолютную ссылку, например $A$2:
=RegExpReplace(A5; $A$2; "")
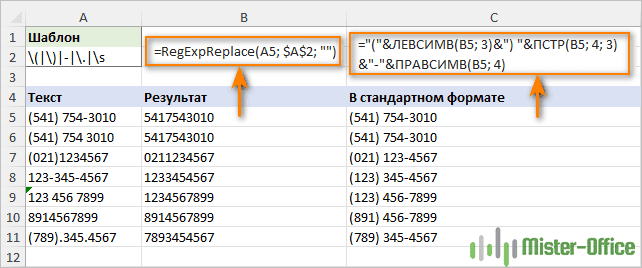
А затем вы можете стандартизировать отображение телефонного номера по своему усмотрению, используя оператор конкатенации (&) и текстовые функции, такие как ПРАВСИМВ, ЛЕВСИМВ и ПСТР.
Например, чтобы записать все номера телефонов в формате (123) 456-7890, формула примет следующий вид:
="("&ЛЕВСИМВ(B5; 3)&") "&ПСТР(B5; 4; 3)&"-"&ПРАВСИМВ(B5; 4)
Где B5 – ячейка, в которой записана предыдущая формула RegExpReplace.
Пример вы видите на скриншоте выше.
Удаляем группы символов с помощью регулярного выражения
В одном из наших руководств мы рассмотрели, как удалить нежелательные символы в Excel с помощью встроенных функций. Регулярные выражения значительно упрощают эту работу. Вместо того, чтобы перечислять все символы, которые нужно удалить, просто укажите те, которые хотите оставить :)
Шаблон основан на инвертированных символьных классах – перед списком символов помещается этот значок ^, чтобы искать любой одиночный символ НЕ в скобках. Квантификатор + заставляет рассматривать последовательные символы как одно совпадение, так что замена выполняется для соответствующей подстроки, а не для каждого отдельного символа.
В зависимости от ваших потребностей выберите одно из следующих регулярных выражений.
Чтобы удалить не буквенно-цифровые символы, то есть все символы, кроме букв и цифр:
[^0-9a-zA-Zа-яА-Я]+
Чтобы удалить все символы, кроме букв, цифр и пробелов:
[^0-9a-zA-Zа-яА-Я\ ]+
Чтобы удалить все символы, кроме букв, цифр и подчеркивания, вы можете использовать \W, обозначающий любой символ, НЕ являющийся буквенно-цифровым символом или подчеркиванием:
\W+
Если вы хотите сохранить некоторые другие символы, например знаки препинания, поместите их в квадратные скобки.
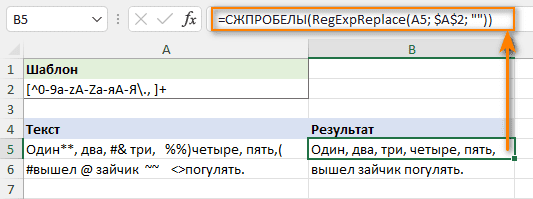
Например, чтобы удалить любой символ, кроме буквы, цифры, точки, запятой или пробела, используйте следующее регулярное выражение:
[^0-9a-zA-Zа-яА-Я\., ]+
Это успешно удаляет все специальные символы. Но если в тексте встречалось подряд несколько пробелов, то остается лишний пробел.
Чтобы исправить это, вы можете вложить указанную выше функцию в СЖПРОБЕЛЫ, которая заменяет несколько пробелов одним.
=СЖПРОБЕЛЫ(RegExpReplace(A5; $A$2; ""))
Результат вы видите на скриншоте ниже.
Регулярное выражение для удаления нечисловых символов
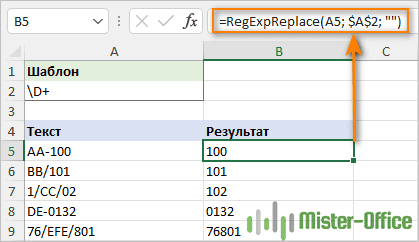
Чтобы удалить все нечисловые символы из строки, вы можете использовать либо эту длинную формулу, либо одно из очень простых регулярных выражений, перечисленных ниже.
Соответствует любому символу, который НЕ является цифрой:
\D+
А вот так можно найти все нечисловые символы с помощью отрицательных классов:
[^0-9]+
или
[^\d]+
В результате удалены все символы, кроме цифр:
Совет. Если ваша цель – удалить текст и разнести оставшиеся числа в отдельные ячейки или поместить их всех в одну ячейку, разделенную каким-то разделителем, используйте функцию RegExpExtract, как описано в статье «Как извлекать числа из строки с помощью регулярных выражений».
Регулярное выражение для удаления всего после пробела
Чтобы стереть все, что находится после пробела, используйте символ пробела – обычный или такой \s, чтобы найти первый пробел. А затем примените .*, чтобы найти любые символы после него.
Если у вас есть однострочные строки, которые содержат только нормальные пробелы (значение 32 в 7-битной системе ASCII), на самом деле не имеет значения, какое из следующих регулярных выражений вы используете. Если же в ячейке текст записан с переносами строки, то это имеет значение.
Чтобы удалить все после символа пробела, используйте это регулярное выражение:
Шаблон: .*
=RegExpReplace(A5; “.*”; "")
Эта формула удалит все, что находится после первого пробела в каждой строке. Чтобы результаты отображались правильно, обязательно включите в формате ячейки перенос текста.
Чтобы удалить все, что находится после пробела (включая другие пробелы, табуляцию, возврат каретки и перенос строки), используйте такое регулярное выражение:
Шаблон: \s.*
=RegExpReplace(A5; "\s.*"; "")
Поскольку \s соответствует нескольким различным типам пробелов, включая новую строку (\n), эта формула удаляет все, что находится после первого пробела в ячейке, независимо от того, сколько в ней строк.
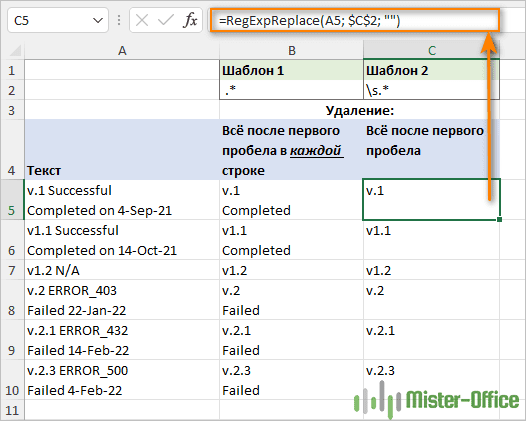
На скриншоте выше вы видите результат работы этих двух шаблонов. В первом случае удалено всё, что находится после пробела, в каждой строке текста в ячейке. Во втором случае удалено всё, начиная с первого пробела и до конца текста.
Удаление текста после определенного символа
Используя методы из предыдущего примера, вы можете удалить текст после любого указанного вами символа, а не только пробела.
Чтобы обрабатывать каждую строку текста отдельно:
Общий шаблон: символ. *
В однострочных строках это удалит все, что находится после символ. В многострочных строках каждая строка будет обрабатываться отдельно, потому что в версии VBA Regex точка . соответствует любому символу, кроме новой строки.
Чтобы обработать все строки текста как одну строку:
Общий шаблон: символ (.|\n)*
Чтобы удалить что-либо после символа, включая новые строки, к регулярному выражению добавляется \n.
Например, чтобы удалить текст после первой запятой в строке, попробуйте следующие регулярные выражения:
,. *
,(.|\n)*
На скриншоте ниже вы можете увидеть, чем отличаются результаты.
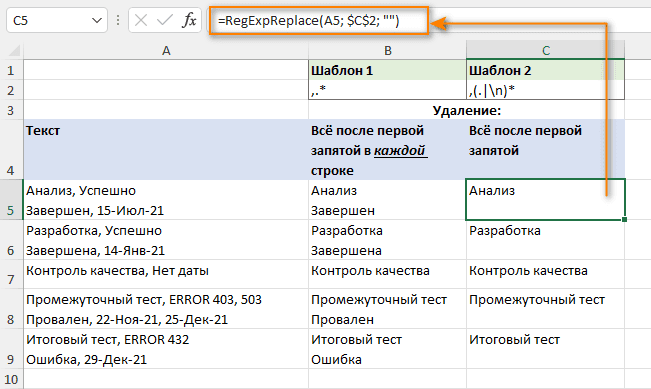
Удалены все символы либо до конца каждой строки, либо до конца всего текста в ячейке.
Регулярное выражение для удаления всего до пробела
При работе с длинными строками текста иногда может потребоваться сделать их короче, удалив одну и ту же часть информации во всех ячейках. Ниже мы обсудим два таких случая.
Удалите все до последнего пробела
Как и в предыдущем примере, регулярное выражение зависит от вашего понимания термина «пробел».
Это регулярное выражение будет соответствовать чему-либо до последнего пробела в строке (добавляются кавычки, чтобы сделать пробел после звездочки заметным).
Шаблон: ".* "
Чтобы получить все символы перед последним пробелом в тексте (включая пробел, табуляцию, возврат каретки и новую строку), используйте это регулярное выражение.
Шаблон: .*\s
Особенно заметна разница на многострочных значениях.
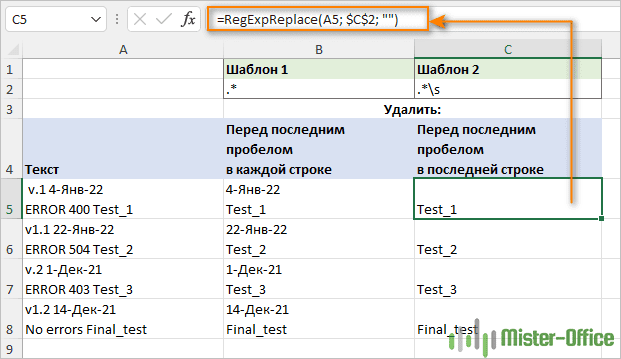
Удалить все перед первым пробелом
Чтобы сопоставить что-либо до первого пробела в строке, вы можете использовать это регулярное выражение:
^[^] * +
С начала строки ^ мы сопоставляем ноль или несколько непробельных символов [^ ]*, за которыми сразу же следует один или несколько пробелов +. Последняя часть добавлена для предотвращения потенциальных пробелов в результатах.
Чтобы удалить текст перед первым пробелом в каждой строке, формула записывается в режиме "все совпадения" по умолчанию (аргумент instance_num опущен):
=RegExpReplace(A5; “^[^ ]* +”; "")
Чтобы удалить текст перед первым пробелом в первой строке и оставить все остальные строки нетронутыми, аргумент instance_num устанавливается в 1:
=RegExpReplace(A5; “^[^ ]* +”; ""; 1)
Можно пометить шаблон в отдельную ячейку и зафиксировать ее абсолютной ссылкой, как это сделано на скриншоте ниже.
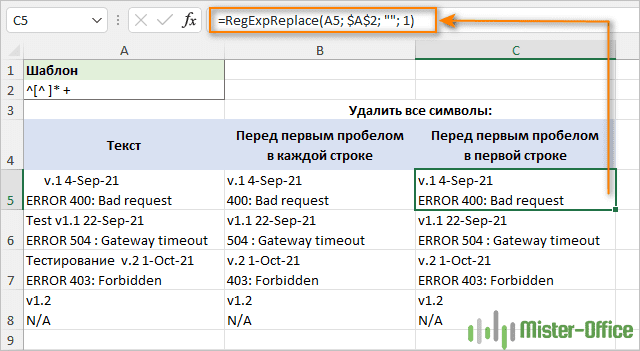
Регулярное выражение для удаления всего перед символом
Самый простой способ удалить весь текст перед определенным символом – использовать такое регулярное выражение:
Общий шаблон : ^[^символ]*символ
В переводе на человеческий язык это означает: «от начала текста, выбрать 0 или более символов, кроме указанного символа, до первого вхождения этого символа».
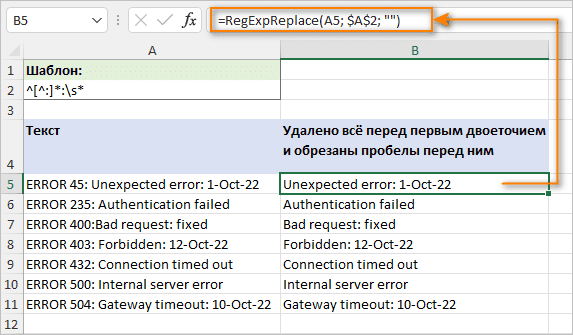
Например, чтобы удалить весь текст перед первым двоеточием, используйте это регулярное выражение:
^[^:]*:
Чтобы избежать пробелов в начале результатов, добавьте в конец пробел \s*. Это удалит все до первого двоеточия и обрежет все пробелы сразу после него:
^[^:]*:\s*
=RegExpReplace(A5; “^[^:]*:\s* ”; "")
Регулярное выражение для удаления всего, кроме
Чтобы удалить все символы из строки, кроме тех, которые вы хотите сохранить, используйте классы символов с отрицанием.
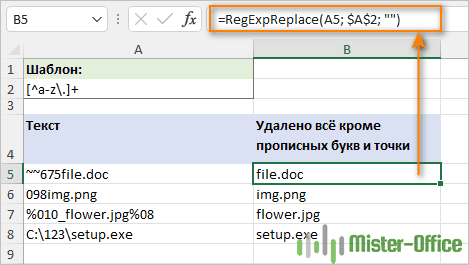
Например, чтобы удалить все символы, кроме строчных букв и точек, регулярное выражение выглядит так:
[^a-zа-я\.]+
Фактически, здесь можно было бы обойтись без квантификатора +, поскольку наша функция заменяет все найденные совпадения. Квантификатор просто делает это немного быстрее – вместо обработки каждого отдельного символа вы заменяете подстроку.
=RegExpReplace(A5; "[^a-zа-я\.]+"; "")
Удаление HTML тегов в Excel при помощи регулярных выражений
Прежде всего, следует отметить, что HTML не является обычным языком, поэтому его синтаксический анализ с использованием регулярных выражений – не самый лучший способ. Тем не менее, регулярные выражения определенно могут помочь удалить теги из ваших ячеек, чтобы сделать ваш набор данных более чистым.
Учитывая, что теги html всегда помещаются в угловые скобки <>, вы можете найти их, используя одно из следующих регулярных выражений.
Отрицательный класс:
Шаблон: <[^>]*>
Здесь мы сопоставляем открывающую угловую скобку, за которой следует ноль или более вхождений любого символа, кроме закрывающей угловой скобки [^>]*, до ближайшей закрывающей угловой скобки.
Ленивый поиск:
<.*?>
Здесь мы сопоставляем все, от первой открывающей скобки до первой закрывающей скобки. Знак вопроса указывает искать как можно меньшее количество символов, пока не будет найдена закрывающая скобка.
Какой бы вариант вы бы ни выбрали, результат будет абсолютно одинаковым.
Например, чтобы удалить все теги html из строки в A5 и оставить текст, формула будет следующей:
=RegExpReplace(A5, "<.*?>", "")
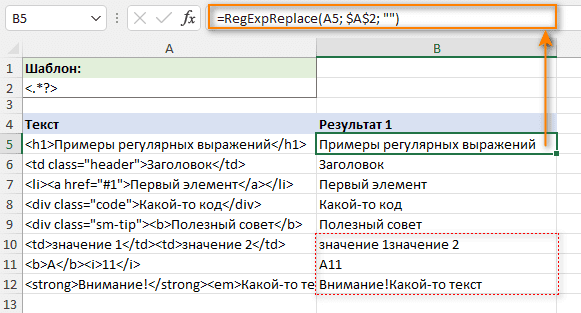
Это решение идеально подходит для однострочного текста (строки 5–9). Для нескольких строк (строки 10–12) результаты сомнительны - тексты из разных тегов сливаются в один. Это правильно или нет? Боюсь, это нелегко решить - все зависит от вашего понимания желаемого результата. Например, в B11 ожидается результат «A1»; в то время как в B10 вы можете захотеть, чтобы «значение1» и «значение2» были разделены пробелом.
Чтобы удалить теги html и разделить оставшийся текст пробелами, вы можете поступить следующим образом:
- Заменить теги пробелами " ", а не пустыми строками:
=RegExpReplace(A5, "<.*?>", " ")
- Сократить несколько пробелов до одного символа пробела:
=RegExpReplace(RegExpReplace(A10; "<[^>]*>"; " "); " +"; " ")
- Обрезать начальные и конечные пробелы:
=СЖПРОБЕЛЫ(RegExpReplace(RegExpReplace(A5; "<[^>]*>"; " "); " +"; " "))
Результат будет примерно таким:
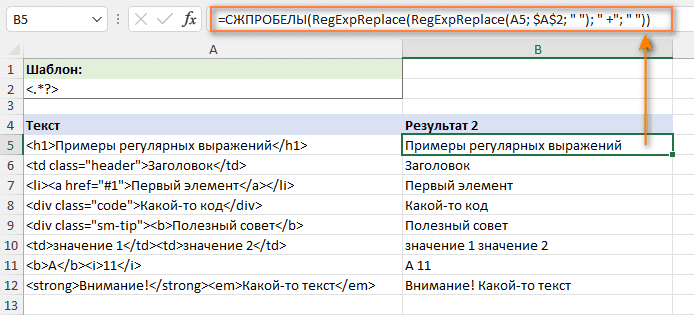
В результате импортированный текст стал совершенно читаемым.
Инструмент удаления символов и текста Ablebits Regex
Если у вас была возможность использовать Ultimate Suite for Excel, вы, вероятно, уже обнаружили новые инструменты Regex, представленные в недавнем выпуске. Прелесть этих функций Regex на основе .NET заключается в том, что они, во-первых, поддерживают полнофункциональный синтаксис регулярных выражений, свободный от ограничений VBA RegExp, и, во-вторых, не требуют вставки какого-либо кода VBA в ваши книги, поскольку вся интеграция кода выполняется автоматически.
Ваша часть работы - создать регулярное выражение и передать его функции :) Позвольте мне показать вам, как это сделать, на практическом примере.
Как удалить текст в скобках с помощью регулярного выражения
В длинных текстовых строках менее важная информация часто заключена в [скобки] и (круглые скобки). Как удалить эти ненужные подробности, сохранив при этом все остальные данные?
Фактически, мы уже создали подобное регулярное выражение для удаления тегов html, то есть текста в угловых скобках. Очевидно, что те же методы будут работать и для квадратных и круглых скобок.
Шаблон: (\(.*?\))|(\[.*?\])
Хитрость заключается в использовании ленивого квантификатора (*?) для поиска кратчайшей возможной подстроки. Первая группа (\(.*?\)) соответствует содержимому от открывающей круглой скобки до первой закрывающей скобки. Вторая группа (\[.*?\]) соответствует находящемуся от открывающей квадратной скобки до первой закрывающей скобки. Знак | действует как оператор ИЛИ.
Определив шаблон, давайте «скормим» его нашей функции Regex Remove. Вот каким образом:
- На вкладке «Ablebits Data» в группе «Text» щелкните «Regex Tools» .
- В появившейся слева панели выберите исходные ячейки с текстом, введите регулярное выражение, выберите параметр «Remove (Удалить)» и нажмите кнопку «Remove».
Чтобы получить результаты в виде формул, а не значений, установите флажок Insert as a formula (Вставить как формулу).
Чтобы удалить текст в скобках из строк в A2: A5, мы настраиваем следующие параметры, как на скриншоте ниже:
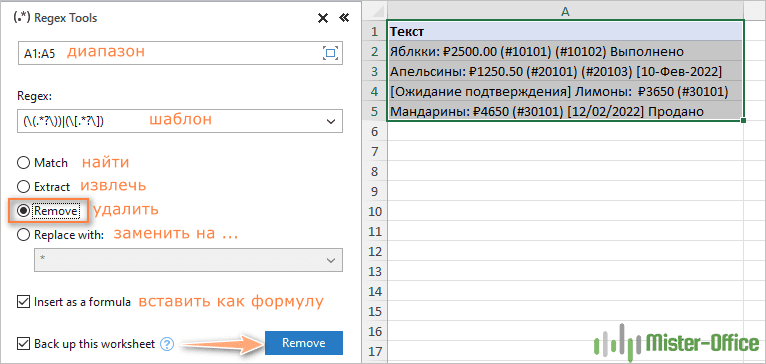
В результате функция AblebitsRegexRemove вставляется в новый столбец рядом с вашими исходными данными.
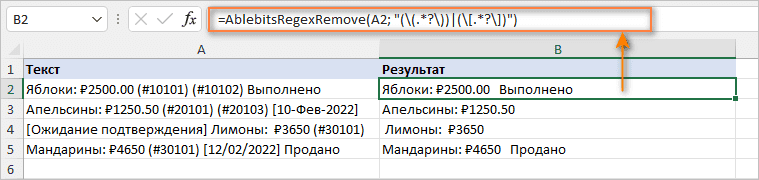
Функцию также можно ввести непосредственно в ячейку через стандартное диалоговое окно «Вставить функцию», где она отнесена к категории AblebitsUDFs .
Поскольку AblebitsRegexRemove предназначена для удаления текста, ей требуются только два аргумента - исходная строка и регулярное выражение. Оба параметра могут быть определены непосредственно в формуле или предоставлены в виде ссылок на ячейки. При необходимости эту настраиваемую функцию можно использовать вместе с любыми стандартными функциями Excel.
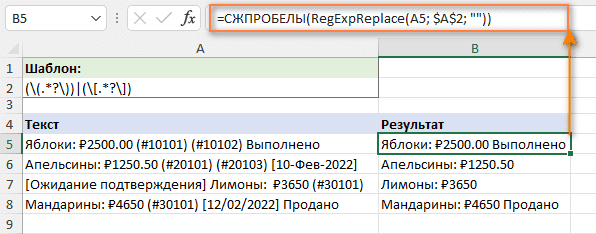
Например, чтобы обрезать лишние пробелы в результирующих строках, вы можете использовать функцию СЖПРОБЕЛЫ:
=СЖПРОБЕЛЫ(RegExpReplace(A5; $A$2; ""))
Вот как удалить текст в Excel с помощью регулярных выражений. Почти так же просто, как купить подписчиков в инстаграм. :) Благодарю вас за чтение!

