В этом руководстве вы узнаете, как использовать регулярные выражения в Excel для поиска и извлечения части текста, соответствующего заданному шаблону.
Microsoft Excel предоставляет ряд функций для извлечения текста из ячеек. Эти функции могут справиться с большинством задач извлечения информации из ячеек на ваших листах. Большинством, но не всеми. Когда текстовые функции не работают, на помощь приходят регулярные выражения. Подождите ... В Excel нет функций регулярных выражений! Действительно, встроенных функций нет. Но нет ничего, что помешало бы использовать свои :)
В этой статье мы рассмотрим следующие вопросы:
Что такое регулярные выражения
Регулярное выражение – это шаблон, состоящий из последовательности символов, который можно использовать для поиска соответствующей последовательности в другой строке.
Регулярные выражения — это инструмент обработки текста для символьных значений. Говоря проще, регулярные выражения хороши для работы с текстом и плохи почти во всем остальном.
На практике это означает, что регулярные выражения плохо подходят для задач, требующих обнаружения смысла (семантики) в тексте, выходящем за пределы уровня символов.
Выполнение более сложных операций с числом, требующих знания его числового значения (то есть его семантики), не по силам регулярным выражениям. Так, найти число в тексте с их помощью легко. А вот найти число в тексте, которое больше 11, но меньше 100, или же чётное число, будет сложно. Для этого нужно распознать значение числа.
Итак, регулярные выражения — это прекрасная замена функциям работы с текстом.
Как добавить пользовательскую функцию RegExp
Чтобы добавить в Excel пользовательскую функцию работы с регулярными выражениями, вставьте следующий ниже код в редактор VBA. Чтобы включить регулярные выражения в VBA, мы используем встроенный объект Microsoft RegExp.
Public Function RegExpExtract(text As String, pattern As String, Optional instance_num As Integer = 0, Optional match_case As Boolean = True)
Dim text_matches() As String
Dim matches_index As Integer
On Error GoTo ErrHandl
RegExpExtract = ""
Set regex = CreateObject("VBScript.RegExp")
regex.pattern = pattern
regex.Global = True
regex.MultiLine = True
If True = match_case Then
regex.ignorecase = False
Else
regex.ignorecase = True
End If
Set matches = regex.Execute(text)
If 0 < matches.Count Then
If (0 = instance_num) Then
ReDim text_matches(matches.Count - 1, 0)
For matches_index = 0 To matches.Count - 1
text_matches(matches_index, 0) = matches.Item(matches_index)
Next matches_index
RegExpExtract = text_matches
Else
RegExpExtract = matches.Item(instance_num - 1)
End If
End If
Exit Function
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End FunctionЕсли у вас мало опыта работы с VBA, может оказаться полезным пошаговое руководство пользователя: Как вставить создать пользовательскую функцию в Excel .
Примечание. Чтобы функция работала, обязательно сохраните файл как книгу с поддержкой макросов (.xlsm). Думаю, здесь может пригодиться инструкция Как правильно сохранить и применять пользовательскую функцию Excel.
Функция RegExpExtract ищет во входной строке значения, которые соответствуют регулярному выражению, и извлекает одно или все найденные совпадения.
Функция имеет следующий синтаксис:
RegExpExtract(text; pattern; [instance_num]; [match_case])
Здесь:
- text (обязательный параметр) - текстовая строка для поиска.
- Pattern (обязательный) – шаблон, регулярное выражение для сопоставления. При вводе непосредственно в формуле шаблон следует заключать в двойные кавычки, так как это текст.
- Instance_num (необязательный) - указывает, какое по счёту совпадение извлекать. Если не указано, возвращает все найденные совпадения (по умолчанию).
- Match_case (необязательный) - определяет, следует ли учитывать регистр текста или игнорировать его. Если ИСТИНА или опущено (по умолчанию), выполняется сопоставление с учетом регистра; если ЛОЖЬ - регистр не учитывается.
Функция работает во всех версиях Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 и Excel 2010.
Важные особенности функции RegExpExtract
Чтобы эффективно использовать эту функцию в Excel, необходимо обратить внимание на несколько важных моментов:
- По умолчанию функция возвращает все найденные совпадения в соседние ячейки, как показано в этом примере . Чтобы получить конкретное вхождение, укажите соответствующий номер аргумента instance_num.
- По умолчанию функция чувствительна к регистру. Для сопоставления без учета регистра установите для аргумента match_case значение ЛОЖЬ.
- Если нужный шаблон не найден, функция ничего не возвращает (пустая строка).
- Если шаблон неправильный, возникает ошибка #ЗНАЧЕН!
Прежде чем вы начнете использовать эту настраиваемую функцию на своих рабочих листах, вам нужно понять, на что она способна. Приведенные ниже примеры представляют несколько распространенных вариантов ее использования и объясняют, почему результат может отличаться в Excel с поддержкой динамических массивов (Microsoft 365 и Excel 2021) и традиционном Excel (2019 и более ранние версии).
Примечание. Примеры регулярных выражений написаны для совершенно простых наборов данных. Мы не можем гарантировать, что они будут безупречно работать с вашими реальными таблицами. Те, кто имеет опыт работы с регулярными выражениями, согласятся, что их написание — это бесконечный путь к совершенству. Почти всегда есть способ сделать его более элегантным или способным обрабатывать более широкий диапазон исходных данных.
Шпаргалка для создания регулярных выражений
| Шаблон | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| \s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| \S | Анти-вариант предыдущего шаблона, т.е. любой символ, кроме пробела. |
| \d | Любая цифра |
| \D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| \w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| \W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] | В квадратных скобках можно указать один или несколько символов, допустимых на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ "крыши" ^, то набор приобретет обратный смысл - на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|счет-фактура|invoice) будет искать в тексте любое из указанных слов. Обычно набор возможных вариантов заключается в круглые скобки. |
| ^ | Соответствие должно начинаться в начале строки. Например, ^\d{3} извлекает "901" из текста "901-333-777" |
| $ | Соответствие должно извлекаться из конца строки. Например, $\d{3} извлекает "777" из текста "901-333-777" |
| \b | Конец слова. Иначе говоря, соответствие должно обнаруживаться на границе между символом \w (алфавитно-цифровым) и символом \W (не алфавитно-цифровым). |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы - специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к символу, который стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например, .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например, \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так \s* означает любое количество пробелов или их отсутствие. |
| {число} или {число1,число2} | Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например \d{6} означает строго шесть цифр, а шаблон \s{2,5} – от двух до пяти пробелов |
Регулярное выражение для извлечения числа из строки
Следуя основному принципу обучения «от простого к сложному», мы начнем с очень простого случая: извлечения числа из строки.
Первое, что вам нужно решить, какое число извлекать: первое, последнее, конкретное вхождение или все числа.
Извлечь первое число
Это настолько просто, насколько простым может быть регулярное выражение. Учитывая, что \d означает любую цифру от 0 до 9, а знак + означает «один или несколько раз», наше регулярное выражение принимает такую форму:
\d+
Установите параметр instance_num равным 1, и вы получите желаемый результат:
=RegExpExtract(A8; "\d+"; 1)
Где A8 - исходная строка.
Для удобства вы можете записать шаблон в отдельную ячейку (например, $A$2) и зафиксировать этот адрес знаком $ :
=RegExpExtract(A8; $A$2; 1)
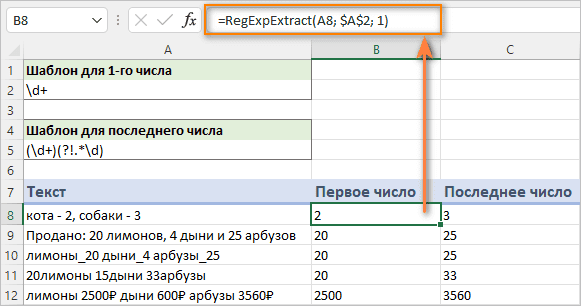
Получить последнее число в строке
Вот шаблон, который можно использовать для извлечения последнего числа в строке:
(\d+)(?!.*\D)
В переводе на обычный язык он означает: найдите число, за которым не следует (до самого конца строки) какое-либо другое число. Чтобы выразить это, мы используем отрицательный просмотр вперед (?!.*\D), что означает, что справа от найденного числа не должно быть другой цифры (\d), независимо от того, сколько других символов находится перед ней.
=RegExpExtract(A8; "(\d+)(?!.*\d)")
Результат вы видите на скриншоте выше.
Подсказки:
- Чтобы получить конкретное вхождение, используйте \d+ для шаблона и соответствующий порядковый номер для instance_num.
- Формула для извлечения всех чисел рассматривается ниже.
Регулярное выражение для извлечения всех совпадений
Понемногу усложняя наш пример, предположим, что вы хотите получить все числа из строки, а не только одно.
Как вы помните, количество извлеченных совпадений определяется необязательным аргументом instance_num. Если нужны все совпадения, тогда вы просто опускаете этот параметр:
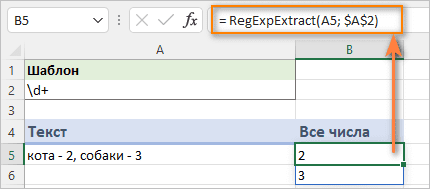
=RegExpExtract(A2; "\d+")
Формула прекрасно работает для одной ячейки, но поведение отличается в Excel с динамическим массивом и нединамических версиях.
Excel 365 и Excel 2021
Благодаря поддержке динамических массивов, обычная формула автоматически распределяется на столько ячеек, сколько необходимо для отображения всех вычисленных результатов.
Excel 2019 - 2007
В не-динамическом Excel приведенная выше формула вернет только первое совпадение. Чтобы получить несколько совпадений, вам нужно сделать её формулой массива. Для этого выберите диапазон ячеек, в которых вы хотите видеть результаты, введите выражение в строку формул и нажмите Ctrl + Shift + Enter, чтобы завершить ввод.
Обратной стороной этого подхода является множество ошибок #Н/Д!, появляющихся в «лишних ячейках». К сожалению, с этим ничего не поделаешь (ни ЕСЛИОШИБКА, ни ЕНД, увы, не этого исправят).
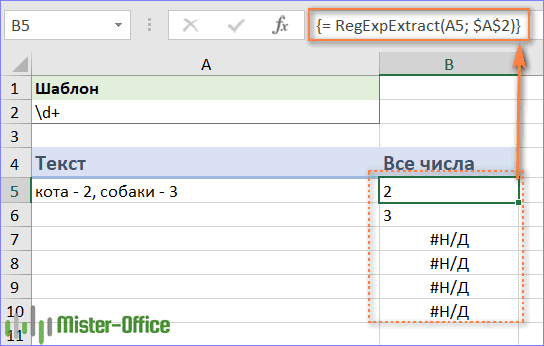
Важно! Это правило в старых версиях Excel действует всегда, когда вам нужно извлечь из текста сразу несколько значений и записать каждое из них в отдельную ячейку.
Как извлечь все совпадения в одну ячейку
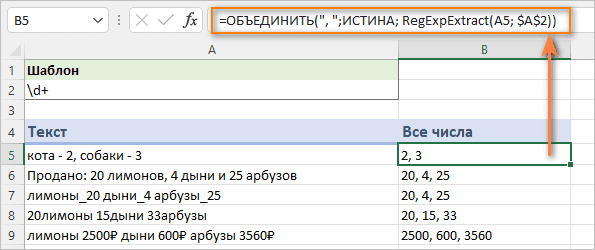
Очевидно, что при обработке столбца данных описанный выше подход не сработает. Просто некуда будет выводить результат, так как в каждой строке есть текст для обработки. В этом случае идеальным решением было бы вернуть все совпадения в одной ячейке. Для этого передайте результаты в функцию ОБЪЕДИНИТЬ() и разделите их любым разделителем, который вам нравится. К примеру, запятой и пробелом после неё:
=ОБЪЕДИНИТЬ("; ";ИСТИНА; RegExpExtract(A5; $A$2))
Примечание. Поскольку функция ОБЪЕДИНИТЬ доступна только в Excel для Microsoft 365, Excel 2021 и Excel 2019, формула не будет работать в более старых версиях.
Извлекаем текст из строки
Извлечение текста из буквенно-цифровой строки в Excel - довольно сложная задача, если использовать формулы. С регулярным выражением это становится проще простого. Просто используйте отрицательный класс, чтобы выбрать все, что не является цифрой.
Шаблон: [^\d]+
Чтобы получить подстроки в отдельных ячейках используем формулу:
=RegExpExtract(A5; "[^\d]+")
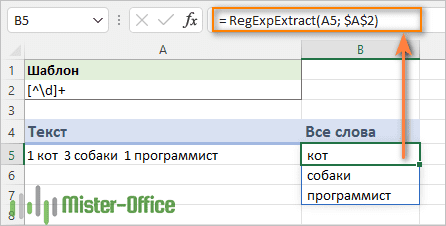
Примечание. В Excel 2019 и ранее не забывайте вводить эту формулу в диапазон ячеек как формулу массива. Это было подробно описано выше.
Чтобы вывести все совпадения в одну ячейку, вложите функцию RegExpExtract в ОБЪЕДИНИТЬ следующим образом:
=ОБЪЕДИНИТЬ("";ИСТИНА; RegExpExtract(A5; $A$2))
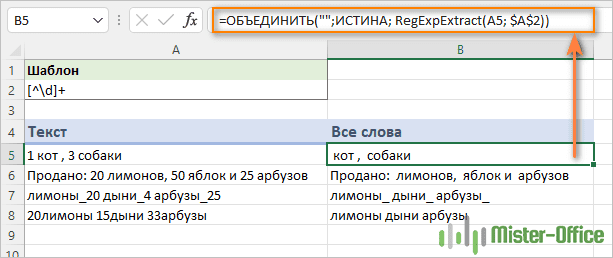
Если нет необходимости между извлекаемым текстом вставлять какие-либо разделители, то можно применить функцию СЦЕП, которая работает в более старых версиях Excel:
=СЦЕП(RegExpExtract(A5;$A$2))
Результат будет таким же, как вы видите на скриншоте выше.
Извлекаем адрес электронной почты из текста
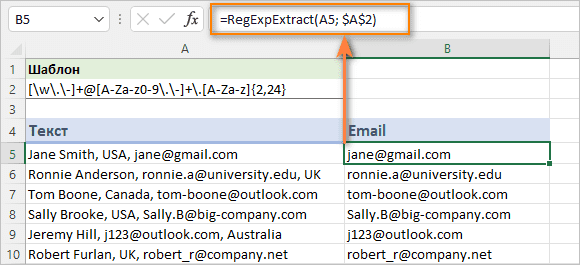
Чтобы извлечь адрес электронной почты из ячейки, содержащей много различной информации, напишите регулярное выражение, которое копирует структуру адреса электронной почты.
Шаблон : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Давайте разберём подробнее:
- [\w\.\-]+ - это имя пользователя, которое может включать 1 или несколько буквенно-цифровых символов, подчеркивания, точки и дефисы.
- @ условное обозначение для адреса электронной почты
- [A-Za-z0-9\.\-]+ - это доменное имя почтового сервера, состоящее из прописных и строчных букв, цифр, дефисов и точек (в случае субдоменов). Подчеркивания здесь недопустимы, поэтому используются 3 разных набора символов (например, A-Z a-z и 0-9) вместо \w, который соответствует любой букве, цифре или подчеркиванию.
- \.[A-Za-z]{2,24} – имя домена первого уровня. Состоит из точки, за которой следуют прописные и строчные буквы. Большинство доменов верхнего уровня состоят из трех букв (например, .com, .org, .ru и т. д.). Но теоретически они могут содержать от 2 до 24 букв (самый длинный зарегистрированный начальный домен).
Предполагая, что текст находится в A5, а шаблон в A2, формула для извлечения адреса электронной почты:
=RegExpExtract(A5; $A$2)
Результат вы видите на рисунке ниже.
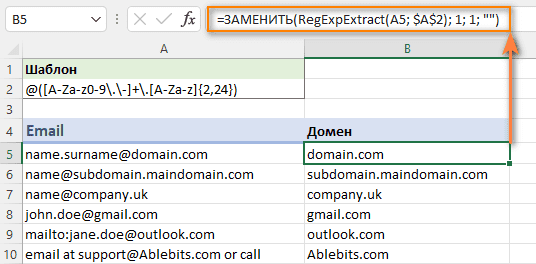
Как извлечь имя домена из электронной почты
Когда дело доходит до извлечения домена электронной почты, первая мысль, которая приходит в голову, - это использовать выражение для поиска текста, который следует сразу за символом @.
Шаблон : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Передаём его в нашу функцию:
=RegExpExtract(A5; "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
И получаем:
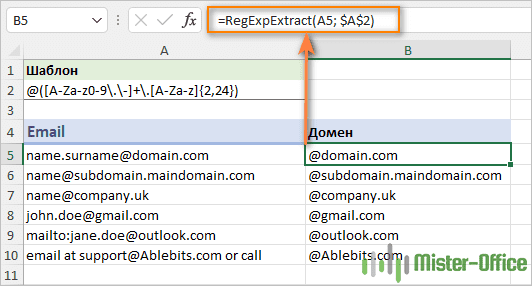
При использовании классических регулярных выражений все, что находится за пределами шаблона, не включается в извлекаемую подстроку. Никто не знает, почему VBA RegEx работает по-другому и зачем-то захватывает еще и символ "@". Чтобы избавиться от него, вы можете удалить первый символ из результата, заменив его пустой строкой.
=ЗАМЕНИТЬ(RegExpExtract(A5; "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24});1;1;””)
На скриншоте ниже вы видите результат без лишних знаков.
Извлечение телефонных номеров
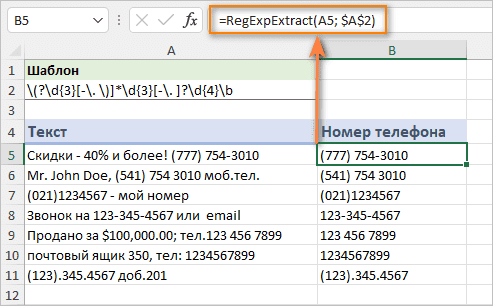
Номера телефонов можно записывать совершенно по-разному, поэтому найти решение, работающее при любых обстоятельствах, практически невозможно. Тем не менее, вы можете записать все форматы, используемые в вашем наборе данных, и попытаться использовать их.
В этом примере мы собираемся создать регулярное выражение, которое будет извлекать телефонные номера в любом из этих форматов:
| (123) 345-6789 | 1233456789 | 123.345.6789 |
| (123) 345 6789 | 123-345-6789 | 123 345 6789 |
| (123)3456789 |
Шаблон : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Первая часть \(?\D{3} соответствует нулю или одной открывающей скобке, за которой следуют три цифры d{3}.
- [-\.\)]*. Выражение в квадратных скобках означает любой из этих символов: дефис, точка, пробел или закрывающая скобка, встречающийся 0 или более раз.
- Затем у нас снова три цифры d{3}, за которыми следует любой дефис, точка или пробел [-\. ]?
- После этого идет группа из четырех цифр \d{4}.
- Наконец, есть граница слова \b, определяющая, что номер телефона, который мы ищем, не может быть частью большего числа.
Полная формула принимает такой вид:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b")
Имейте в виду, что указанное выше регулярное выражение может возвращать несколько ложноположительных результатов, например 123) 456 7899 или (123 456 7899. Приведенная ниже версия устраняет эти проблемы. Однако этот синтаксис работает только в функциях VBA RegExp, а не в классических регулярных выражениях.
Шаблон : (\(\d{3}\)|\d{3})[-\. ]?\d{3}[-\. ]?\d{4}\b
Аналогичным образом можно извлечь из описания товара его артикул, который вставил в ячейку сканер штрих-кодов.
Достаём дату из текста
Регулярное выражение для извлечения даты зависит от формата, в котором она записана. Рассмотрим на примерах.
Для извлечения таких дат, как 21.01.2021 или 01.01.2021, подходит регулярное выражение:
\d{1,2}\/\d{1,2}\/(\d{4}|\d{2})
Формула ищет группу из 1 или 2 цифр d{1,2}, за которой следует косая черта, после которой – другая группа из 1 или 2 цифр, за которой следует косая черта, после которой группа из 4 или 2 цифр (\d{4}|\d{2}). Обратите внимание, что сначала мы ищем 4-значные годы, а только потом 2-значные. Если мы напишем наоборот, из всех чисел, обозначающих годы, будут выбраны только первые две цифры. Это связано с тем, что после того, как первое условие в конструкции ИЛИ выполнено, остальные условия уже не проверяются.
Чтобы извлечь из текста такие даты, как 1 января 21 или 1 января 2021 года, используйте шаблон:
\d{1,2}-[A-Za-z]{3}-\d{2,4}
Он ищет группу из 1 или 2 цифр, за которыми следует дефис, далее за которым следует группа из 3 заглавных или строчных букв, потом - снова дефис, за которым в свою очередь - группа из 4 или 2 цифр.
После объединения этих двух шаблонов мы получаем следующее регулярное выражение:
\b\d{1,2}[\/-](\d{1,2}|[A-Za-z]{3}|[А-Яа-я]{3})[\/-](\d{4}|\d{2})\b
Где:
- Первая часть состоит из 1 или 2 цифр: \d{1,2}
- Вторая часть включает 1 или 2 цифры или 3 буквы русского либо латинского алфавита: (\d{1,2}|[A-Za-z]{3}|[А-Яа-я]{3})
- Третья часть представляет собой группу из 4 либо 2 цифр: (\d{4}|\d{2})
- Разделитель – это косая черта или дефис: [\/-]
- Граница слова \b помещена с обеих сторон, чтобы было понятно, что дата – это отдельное слово, а не часть большей строки.
Как вы можете видеть на скриншоте ниже, функция успешно извлекает даты и исключает подстроки, такие как 11/22/333. Однако она по-прежнему возвращает ложноположительные результаты. В нашем случае подстрока 11-ABC-2222 в A11 технически соответствует формату даты дд-ммм-гггг и поэтому извлекается.
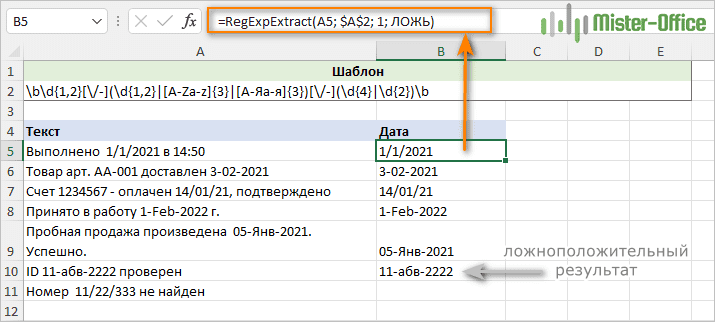
Чтобы исключить такой ошибочный выбор, вы можете заменить часть [A-Za-z]{3}|[А-Яа-я]{3}) полным списком трехбуквенных сокращений месяцев:
\b\d{1,2}[\/-](\d{1,2}|(Янв|Фев|Мар|Апр|Май|Июн|Июл|Авг|Сен|Окт|Ноя|Дек))[\/-](\d{4}|\d{2})\b
Чтобы игнорировать регистр букв, мы устанавливаем последний аргумент нашей пользовательской функции в ЛОЖЬ:
=RegExpExtract(A5; $A$2; 1; ЛОЖЬ)
И на этот раз мы получаем идеальный результат:
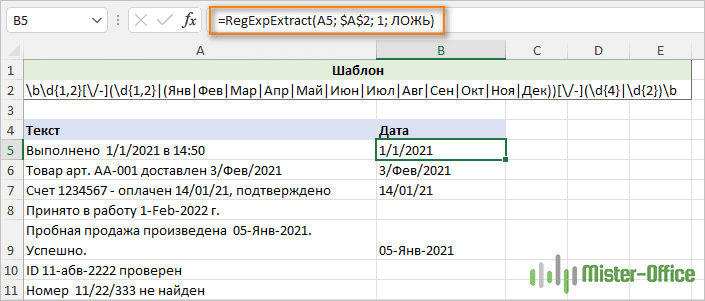
Как видите, все даты успешно извлечены. При этом обработка латиницы в этом шаблоне не была предусмотрена.
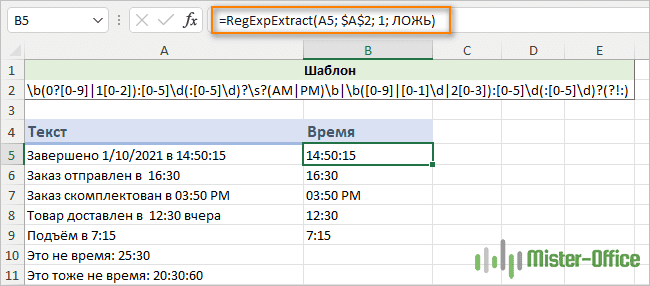
Извлечь время из текста
Чтобы получить время в формате чч:мм или чч:мм:сс , подойдет следующее выражение.
\b(0?[0-9]|1[0-2]):[0-5]\d(:[0-5]\d)?\S?(AM|PM)\b|\b([0-9]|[0-1]\d|2[0-3]):[0-5]\d(:[0-5]\d)?(?!:)
Разбив это регулярное выражение, вы увидите 2 части, разделенные символом | . Это подразумевает логику ИЛИ. Другими словами, мы ищем подстроку, которая соответствует одному из приведенных ниже выражений.
\b([0-9]|[0-1]\d|2[0-3]):[0-5]\d(:[0-5]\d)?(?!:)
Часть часа может быть любым числом от 0 до 23. Чтобы получить ее, используется конструкция ИЛИ ([0-9]|[0-1]\d|2[0-3]), где:
- [0-9] соответствует любому числу от 0 до 9.
- [0-1]\d соответствует любому числу от 00 до 19
- 2[0-3] означает любое числу от 20 до 23
Минуты [0-5]\d - любое число от 00 до 59.
Секунды (:[0-5]\d)? также любое число от 00 до 59. Символ ? (квантификатор) означает ноль или одно появление, поскольку секунды могут быть включены или не включены во значение времени.
Отрицательный просмотр вперед (?! :) добавляется для пропуска заведомо неправильных значений, таких как 20:30:70.
На всякий случай для 12-часового формата времени в шаблон добавлено AM|PM. Поскольку AM/PM может быть как в верхнем, так и в нижнем регистре, мы делаем функцию нечувствительной к регистру:
=RegExpExtract(A5; $A$2; 1; ЛОЖЬ)
Как найти последнее вхождение нужного символа и извлечь текст после него
Регулярное выражение позволяет нам найти последнее вхождение любого указанного символа (тире, двоеточия, точки, запятой, цифры или буквы). А затем уже получить следующую за ним часть текста – дело техники.
Чтобы получить текст после последней точки в строке, используйте регулярное выражение
([^\..]+)$
Подставив его в функцию, получим формулу:
= RegExpExtract(A5; "([^\..]+)$")
Обратите внимание на конструкцию \..
Она как раз и обозначает любой символ . , следующий после точки \. Знак + обозначает, что таких символов может быть сколь угодно много. А $ указывает, что все эти операции происходят в конце строки.
Из исходной строки. вида A.B.C.DD-EEE мы получаем DD-EEE.
Вы можете заменить \. на любой другой символ по вашему усмотрению. К примеру, регулярное выражение ([^-.]+)$ возвратит нам все, что следует после последнего тире, то есть ЕЕЕ.
Надеюсь, приведенные выше примеры дали вам некоторые идеи о том, как использовать регулярные выражения в ваших таблицах Excel.
К сожалению, не все функции классических регулярных выражений поддерживаются в VBA. Если ваша задача не может быть выполнена с помощью VBA RegExp, я рекомендую вам прочитать следующий раздел, в котором обсуждаются гораздо более мощные функции .NET Regex.
Пользовательская функция Regex на основе .NET для извлечения текста в Excel
В отличие от функций VBA RegExp, которые может написать любой пользователь Excel, .NET RegEx - это область деятельности разработчика. Microsoft .NET Framework поддерживает полнофункциональный синтаксис регулярных выражений, совместимый с Perl 5. Эта статья не научит вас писать такие функции (я не программист и не имею ни малейшего представления о том, как это сделать :)
Четыре мощные функции, обрабатываемые стандартным механизмом .NET RegEx, уже написаны и включены в надстройку Ultimate Suite. Далее мы продемонстрируем некоторые практические применения функции, специально разработанной для извлечения текста в Excel.
Предполагая, что у вас установлена последняя версия Ultimate Suite, извлечение текста с использованием регулярных выражений сводится к этим двум шагам:
- На вкладке «Ablebits Data» в группе «Text» щелкните «Regex Tools» .
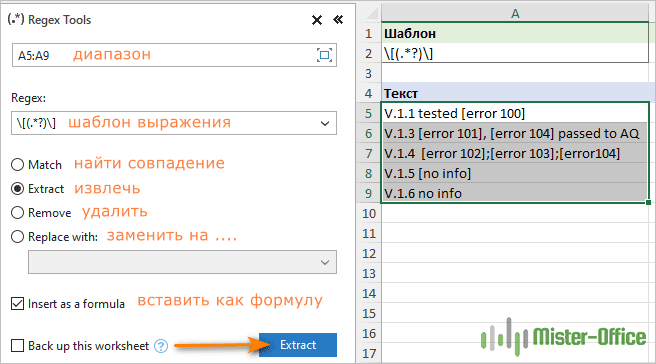
- На панели «Regex Tools» выберите исходные данные, введите свой шаблон регулярного выражения и выберите параметр «Extract (Извлечь)». Чтобы получить результат как пользовательскую функцию, а не как значение, установите флажок «Insert as formula (Вставить как формулу)». Когда закончите, нажмите кнопку «Extract (Извлечь)».
Результаты появятся в новом столбце справа от исходных данных:
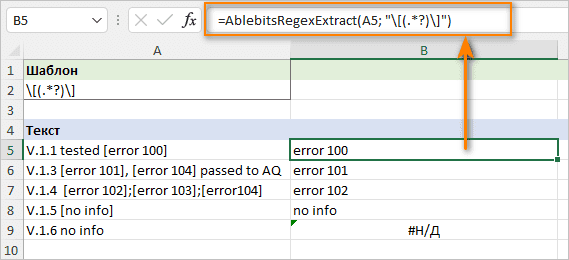
Эта пользовательская функция имеет следующий синтаксис:
AblebitsRegexExtract (ссылка, регулярное_выражение)
Где:
- Ссылка (обязательно) - ссылка на ячейку, содержащую исходную строку.
- Regular_expression (обязательно) - шаблон регулярного выражения для сопоставления.
Важное замечание! Функция работает только при установленном Ultimate Suite for Excel.
Примечания по использованию
Чтобы сделать процесс обучения более плавным, а опыт - более приятным, обратите внимание на следующие моменты:
- Чтобы создать формулу, вы можете использовать наши инструменты для регулярных выражений или диалоговое окно «Вставить функцию» в Excel или ввести полное имя функции в ячейку. После того, как формула вставлена, вы можете управлять ею (редактировать, копировать или перемещать), как любой собственной формулой.
- Шаблон, который вы вводите на панели инструментов Regex, переходит ко второму аргументу. Также можно сохранить регулярное выражение в отдельной ячейке. В этом случае просто используйте ссылку на ячейку для второго аргумента.
- Функция извлекает первое найденное совпадение.
- По умолчанию функция чувствительна к регистру. Для сопоставления без учета регистра используйте шаблон (?I).
- Если совпадение не найдено, возвращается ошибка #Н/Д.
Извлечение строки между двумя символами
Чтобы получить текст между двумя символами, вы можете использовать либо группу захвата, либо просмотр.
Допустим, вы хотите выделить текст между скобками.
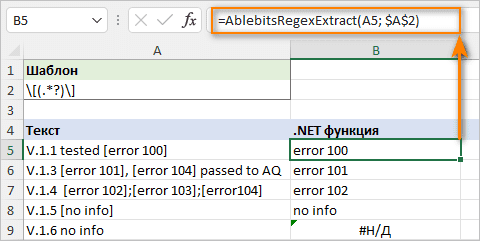
Шаблон 1 : \[(.*?)\]
Шаблон 2 : (?<=\[)(.*?)(?=\])
С шаблоном в A2 формула выглядит следующим образом:
=AblebitsRegexExtract(A5; $A$2)
Как получить все совпадения
Как уже упоминалось, функция AblebitsRegexExtract может извлекать только одно совпадение. Чтобы получить все совпадения, вы можете использовать функцию VBA, которую мы обсуждали ранее. Однако есть одно предостережение - VBA RegExp не поддерживает захват групп, поэтому приведенный выше шаблон также вернет «граничные» символы, в нашем случае квадратные скобки.
Чтобы избавиться от скобок, заменяйте их пустыми строками (""), используя следующую формулу:
=ПОДСТАВИТЬ(ПОДСТАВИТЬ(ОБЪЕДИНИТЬ(", ";ИСТИНА; RegExpExtract(A5; $A$2)); "]"; "");"[";"")
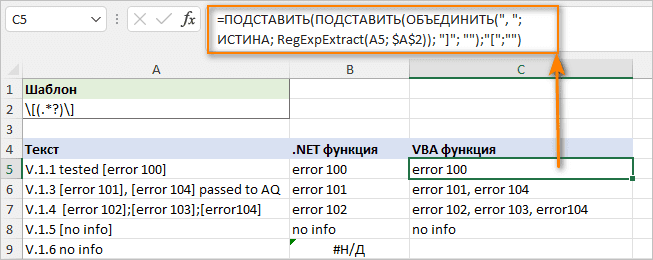
Для удобства чтения мы используем запятую в качестве разделителя.
Получаем текст между двумя строками
Подход, который мы разработали для выделения текста между двумя символами, также будет работать для выделения текста между двумя строками.
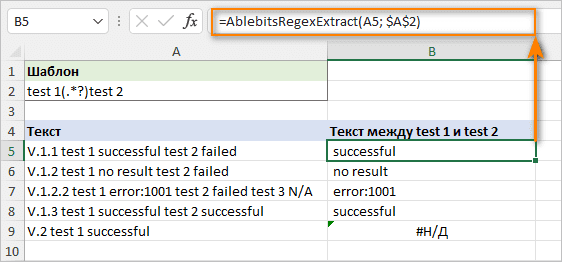
Например, чтобы получить все, что находится между «test 1» и «test 2», используйте следующее регулярное выражение.
Шаблон : test 1(.*?)test 2
Полная формула:
=AblebitsRegexExtract(A5; "test 1(.*?)test 2")
Достаём домен из URL
Даже с использованием регулярных выражений извлечение доменных имен из URL-адресов – нетривиальная задача. В зависимости от вашей конечной цели выберите одно из следующих регулярных выражений.
Чтобы получить полное доменное имя, включая поддомены
Шаблон : (?:https?\:|^|\S)\/\/(((?:[A-Za-z\d\-\.]{2,255}\.)?[A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24})
Чтобы получить домен второго уровня без поддоменов
Шаблон : (?:Https?\:|^|\S)\/\/(?:[A-Za-z\d\-\.]{2,255}\.)?([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24})
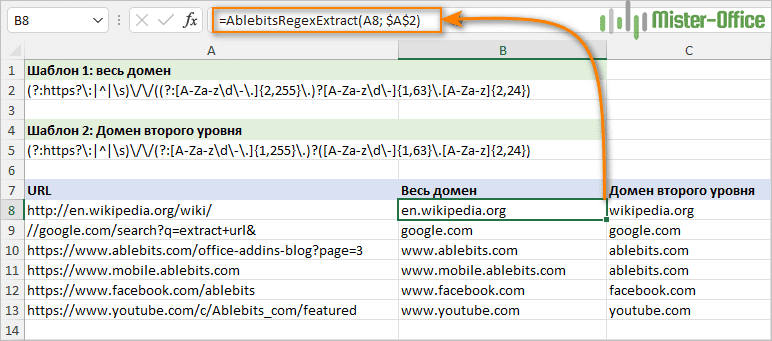
Теперь давайте посмотрим, как эти регулярные выражения работают на примере текста "https://www.mobile.ablebits.com" в качестве образца URL:
- (?:https?\:|^|\s) - шаблон, который определяет, но не извлекает подстроку, которой предшествует одно из следующих: https, http, начало строки (^), символ пробела (\s). Последние два элемента включены для обработки URL-адресов, относящихся к протоколу, например "//google.com".
- \/\/- две косые черты (каждой из них предшествует обратная косая черта, чтобы избежать особого назначения косой черты в коде шаблона и интерпретировать ее буквально).
- (?:[A-Za-z\d\-\.]{2,255}\.)? – шаблон для определения доменов третьего, четвертого и т. д., если таковые имеются ( 11-я строка в нашем примере URL). Поддомен может иметь длину от 2 до 255 символов, отсюда и квантификатор {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) – шаблон для извлечения домена второго уровня. Максимальная длина домена второго уровня - 63 символа. Самый длинный из существующих в настоящее время доменов состоит из 24 символов.
В зависимости от того, какое регулярное выражение введено в A2, приведенная ниже формула даст разные результаты:
=AblebitsRegexExtract(A5; $A$2)
На скриншоте ниже вы видите пример извлечения как полного доменного имени со всем поддоменами, так и только домена второго уровня.
Вот как можно извлекать части текста в Excel с помощью регулярных выражений. Благодарю вас за чтение!

